Zarządzanie incydentami
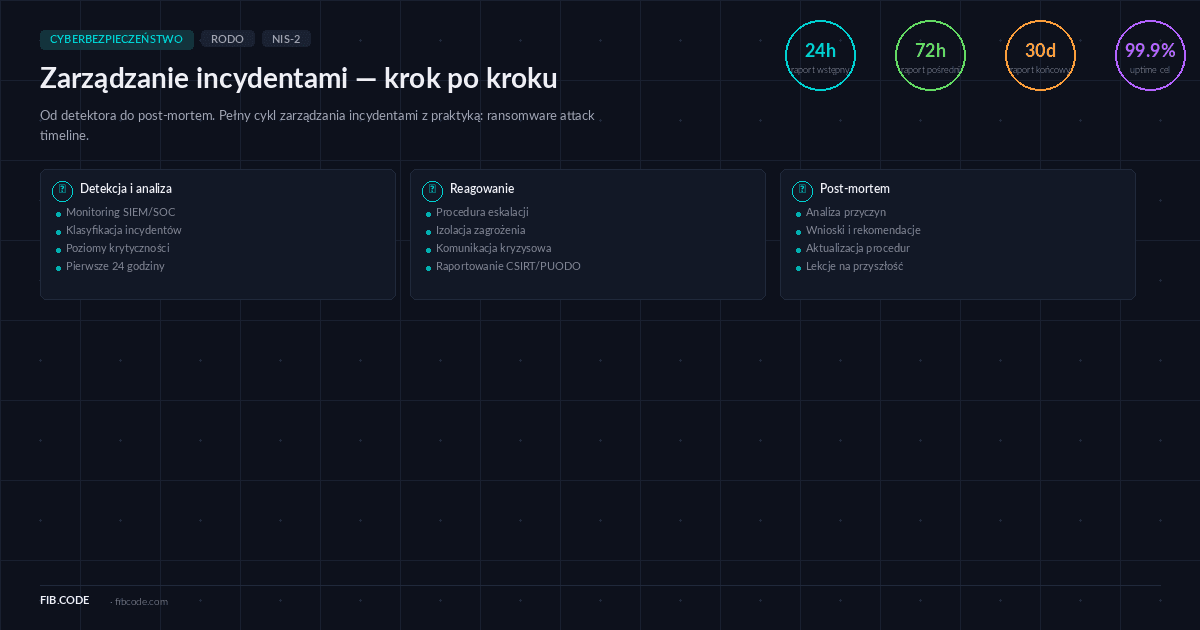
Incydent bezpieczeństwa to każde zdarzenie mogące zagrozić poufności, integralności lub dostępności systemów informacyjnych. W rzeczywistości biznesowej incydenty są niechybne — pytanie nie jest „czy do nas dojedzie", ale „kiedy" i „czy będziemy przygotowani". Organizacja, która nie ma procedury zarządzania incydentami, zmierzy się z kryzysem chaosem, panikował i nikoordynowanymi działaniami, które mogą znacznie pogorszyć sytuację. Artykuł 33 RODO wymaga powiadomienia PUODO o naruszeniu danych osobowych w ciągu siedemdziesięciu dwóch godzin od odkrycia naruszenia, a artykuł 34 wymaga powiadomienia osób, których dane dotyczy, jeśli ryzyko jest wysokie. NIS2 nakłada jeszcze bardziej restrykcyjne wymogi raportowania dla operatorów usług krytycznych. ISO 27001 w załącznikach A.5.24 do A.5.28 określa procedury dla detekcji, analizy i reagowania na incydenty bezpieczeństwa.
Fazy zarządzania
Proces zarządzania incydentami zwyczajowo dzieli się na sześć faz: przygotowanie, detekcja i analiza, zawieranie, eradykacja, odzyskiwanie, i lekcje wyciągnięte. Każda faza ma jasno określone cele, osoby odpowiedzialne i procedury.
Artykuł 33 RODO wymaga zawiadomienia PUODO w ciągu 72 godzin.
Faza przygotowania jest najważniejsza i często najzaniedbywana. To w czasie pokoju musimy zbudować infrastrukturę, procedury i zespoły, które będą działać pod presją w przypadku incydentu. Przygotowanie obejmuje wiele elementów. Pierwszy to wdrożenie systemu detekcji zagrożeń — może to być rozwiązanie SIEM (Security Information and Event Management) takie jak Splunk czy IBM QRadar, które agreguje logi z całej infrastruktury i identyfikuje podejrzane aktywności. Drugie to ustanowienie zespołu reagowania na incydenty (Incident Response Team, IRT) obejmującego pracowników z IT, bezpieczeństwa, zarządzania, prawników i PR. Trzecie to opracowanie dokumentu procedury zarządzania incydentami opisującego etapy, role i komunikację. Czwarte to wdrożenie systemów kopii zapasowych i disaster recovery — bez sprawnej kopii zapasowej, organizacja całkowicie bezbronna w obliczu ransomware. Piąte to regularne szkolenia zespołu IRT, aby wszyscy znali swoje role i procedury.
Detekcja i analiza
Faza detekcji i analizy zaczyna się, gdy system lub pracownik zauważy coś podejrzanego. To może być alarm z systemu SIEM, pracownik zauważający dziwny proces na komputerze, lub znalezienie śladu ataku w logach. W tym momencie ktoś z zespołu bezpieczeństwa lub IT powinien uruchomić procedurę incydentową. Pierwszy krok to potwierdzenie, że rzeczywiście dochodzi do incydentu — czasami alarmy są fałszywe. Jeśli potwierdzono incydent, zespół zaczyna zbierać informacje: co dokładnie się stało, które systemy są zainfekowane, kiedy to się zaczęło, jak wiele danych mogło być zagrożone. Ta analiza powinna być przeprowadzona pod nadzorem osób technicznych, ale jednocześnie musi mieć świadomość wymogów prawnych — jeśli incydent obejmuje dane osobowe, to kwalifikuje się jako naruszenie danych (data breach) w rozumieniu RODO i musi być raportowane.
Zawieranie incydentu
Faza zawierania ma na celu ograniczenie szkód i zapobiegnięcie rozprzestrzenianiu się incydentu. Jeśli atakujący ma dostęp do systemu, zawieranie oznacza, że natychmiast ograniczamy jego możliwości. Konkretnie, może to oznaczać odłączenie zainfekowanego serwera od sieci, resetowanie haseł dla użytkowników, których konta mogły być skompromitowane, blokowanie podejrzanych adresów IP na firewallu, lub czasowe wyłączenie dostępu VPN. W przypadku ransomware, zawieranie jest krytyczne — im szybciej odłączymy zainfekowane systemy od sieci, tym mniejsza szansa, że ransomware rozprzestrzeni się na inne maszyny.
Eradykacja i odzyskiwanie
Faza eradykacji polega na usunięciu atakującego z infrastruktury. To nie jest tak proste, jak założenie może wskazywać. Jeśli atakujący zainstalował backdoor (ukryte wejście do systemu), zainstalowanie poprawki bezpieczeństwa nie wystarczy — musimy znaleźć i usunąć backdoor. W przypadku ransomware, eradykacja oznacza identyfikację i usunięcie malware z wszystkich zainfekowanych systemów. Ta faza powinna być przeprowadzona bardzo ostrożnie, ponieważ jeśli nie usuniemy w pełni zagrożenia, atakujący może powrócić i wznowić atak. Wiele organizacji błędnie zakłada, że po wdrożeniu poprawki bezpieczeństwa problem jest rozwiązany, a następnie jest zaskoczone, kiedy atakujący powraca kilka dni lub tygodni później.
Faza odzyskiwania polega na przywróceniu systemów do normalnego funkcjonowania. W przypadku zainfekowanych serwerów, może to oznaczać przeprowadzenie czystej instalacji systemu operacyjnego i przywrócenie danych z czystej kopii zapasowej. W przypadku ransomware, jeśli organizacja ma dostęp do kopii zapasowych, może przywrócić pliki bez płacenia okupu (co jest również zalecane, ponieważ płacenie chaotycznym bywa nieskuteczne, a wspiera przestępczość). Jednak ta faza musi być przeprowadzona ostrożnie — jeśli przywrócimy pliki z kopii zapasowej, która już była zainfekowana, to znowu zainfekujemy systemy.
Postmortem i wnioski
Ostatnia faza, lekcje wyciągnięte (lessons learned), jest gdzie często organizacje zaniedbują. Po incydencie należy przeprowadzić postmortem — spotkanie zespołu IRT, gdzie analizuje się, co poszło dobrze, co źle, i co można ulepszyć. Postmortem powinno być niestresujące i skupione na procesach, nie na winieniu osób — celem jest nauka, nie karanie. Wynikami powinno być opracowanie listy rekomendacji, które zostaną wdrożone, aby zapobiec podobnym incydentom w przyszłości.
Zawieranie incydentu jest kluczowe dla ograniczenia szkód.
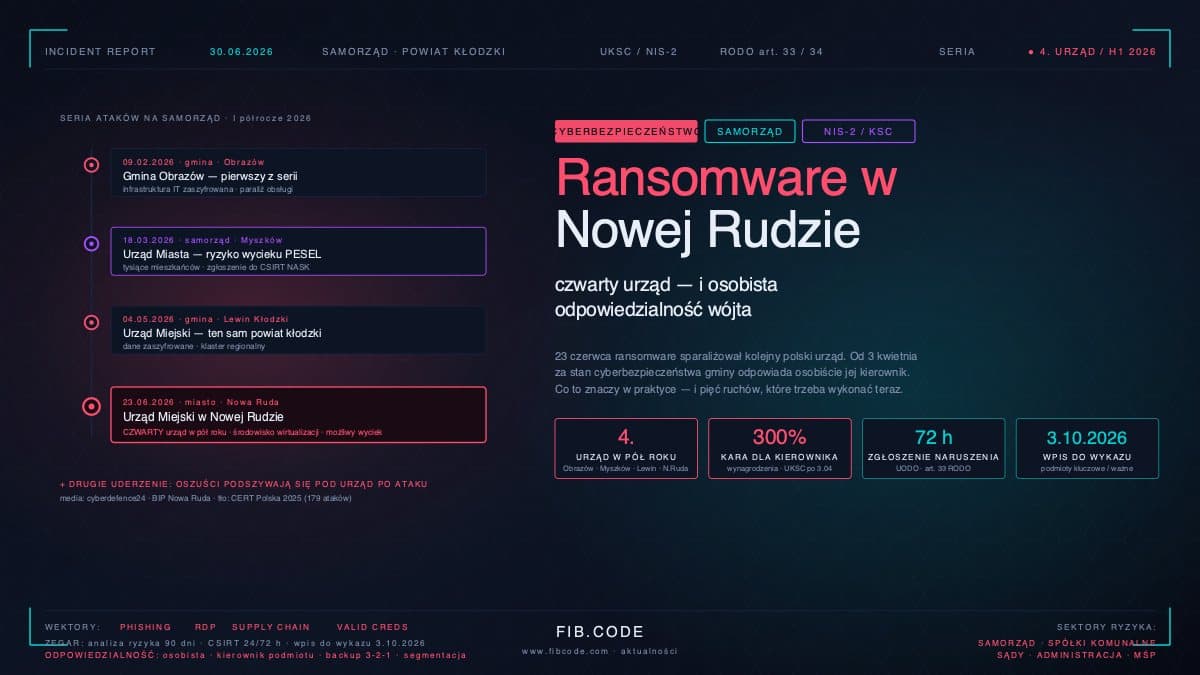
Aby zobrazować ten proces, rozważmy praktyczny scenariusz: poniedziałek, godz. 15:30, administrator sieciowy zauważa alarm z systemu monitoring serwera File Server — nienormalnie wysoka aktywność dysku, a pracownicy zgłaszają, że mają problemy z dostępem do plików. Administrator otwiera procedurę zarządzania incydentami i powiadamia kierownika bezpieczeństwa. Po krótkiej analizie, kierownik bezpieczeństwa stwierdza, że to wygląda na atak ransomware — na ekranach użytkowników pojawia się wiadomość z żądaniem zapłaty i informacją, że wszystkie pliki zostały zaszyfrowane. Procedura incydentowa jest uruchomiona, i w ciągu pięciu minut zespół IRT zbiera się na spotkaniu kryzysowym. Decyzja: natychmiast odłączamy File Server od sieci, informujemy wszystkich użytkowników, aby wyłączyli komputery, aby uniknąć rozprzestrzenia się malware. Jeśli możliwe, wyłączamy VPN firmy, aby zapobiec dostępowi zdalnym. Jednocześnie, trzeba przygotować komunikację dla kierownictwa i, w ostateczności, dla klientów i mediów.
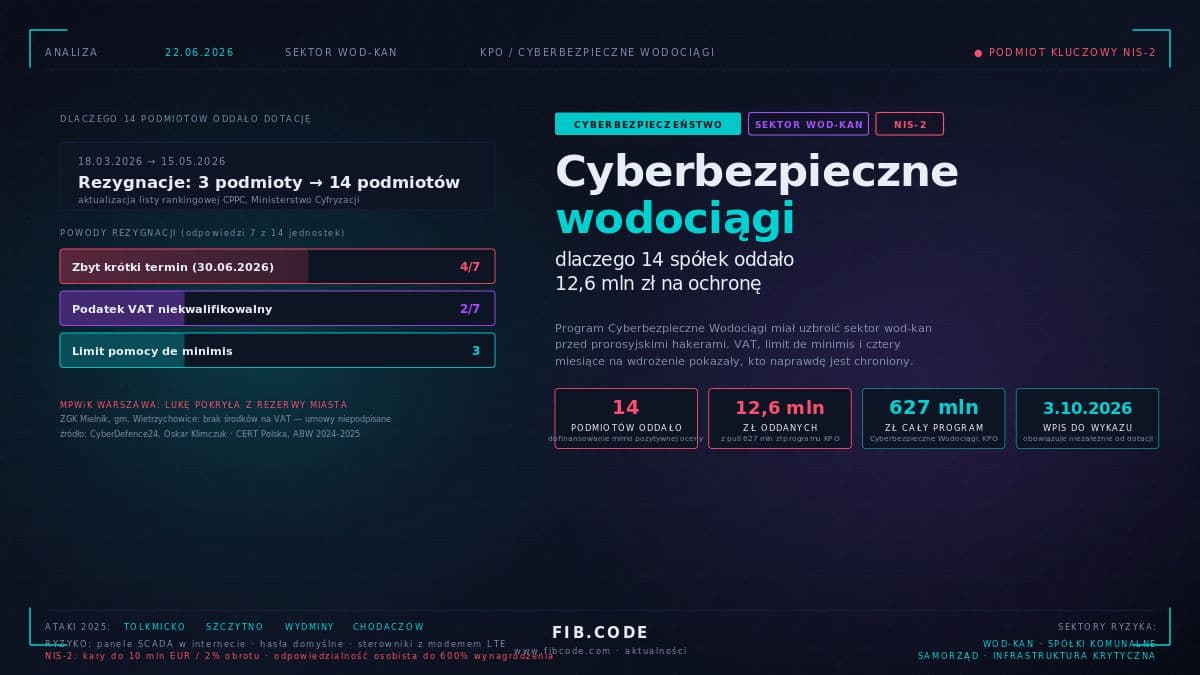
W tym scenariuszu, godz. 16:00, zespół stwierdza, że atakujący ma dostęp do sieciowych dysków. Godzina 16:30, analiza wskazuje, że atak nastąpił przez słabą konfigurację serwera RDP (Remote Desktop Protocol), co pozwoliło atakującemu na brutalny atak siłowy na hasło administratora. Godzina 17:00, wszystkie systemy są odłączone od sieci. Godzina 17:30, kierownik bezpieczeństwa musi zadecydować: czy raportować do PUODO teraz, czy czekać, aż będą bardziej dokładne informacje? RODO nie pozwala czekać zbyt długo — naruszenie musi być raportowane w ciągu siedemdziesięciu dwóch godzin. W tym scenariuszu, postanawia się raportować do PUODO we wtorek rano, po zebraniu więcej informacji. Jednocześnie, zespół rozpoczyna pracę nad identyfikacją, które dane zostały skompromitowane — RODO wymaga powiadomienia osób, których dane dotyczy, jeśli jest wysokie ryzyko dla ich praw i wolności.
Wtorek, godz. 9:00, zespół potwierdza, że zainfekowana jest cała infrastruktura plików, obejmująca dane wszystkich klientów firmy. Należy powiadomić PUODO. Zostaje przygotowana zawiadomienie (notatka zawierająca co się stało, kiedy to się stało, ile danych dotyczy, jaki jest potencjalny wpływ na osoby, których dane dotyczy, jakie działania są podejmowane) i przesłana do PUODO drogą elektroniczną. Równolegle, zespół zaczyna pracę nad eradykacją — analiza wskazuje, że atakujący był w systemie przez co najmniej cztery dni zanim zostały zaszyfrowane pliki. Jeśli jest taka możliwość, przeprowadzana jest kryminalistyka cybernetyczna (forensics) — analiza logów i dysku w poszukiwaniu pozostawionego backdoora. Czwartek, po trzech dniach pracy, zespół potwierdza, że atakujący został wyeliminowany z systemu, i rozpoczyna się odzyskiwanie — przywrócenie plików z kopii zapasowej, która wiadomo, że nie była zainfekowana.
Równolegle z fazami technicznymi, zespół musi zarządzać komunikacją. Pracownicy muszą wiedzieć, co się stało i co powinni robić. Kierownictwo musi być na bieżąco o postępach. Klienci muszą być powiadomieni o tym, że ich dane mogły być zagrożone — to powinno być komunikat uczciwą i przejrzysty. PR musi być przygotowany do udzielenia odpowiedzi mediom.
Dokumentacja jest krytyczna. Każde działanie w trakcie incydentu powinno być zalogowane — kto co robił, kiedy, jakie decyzje zostały podjęte. Ta dokumentacja nie tylko pomaga w zrozumieniu, co się stało, ale będzie również ważna w przypadku postępowania regulacyjnego czy pozwu sądowego.
Po incydencie, postmortem powinno zaproponować działania naprawcze. W scenariuszu z RDP, takie działania mogłyby obejmować: aktywowanie uwierzytelniania wieloskładnikowego na wszystkie konta administratora, zmianę domyślnego portu RDP (choć to nie jest „bezpieczeństwo przez niejasność", bardzo zmniejsza skanowanie automatyczne), wdrożenie bardziej restrykcyjnego firewall policy, która ogranicza dostęp do usług administracyjnych tylko z autoryzowanych IP, czy wdrożenie segmentacji sieci, która ogranicza rozprzestrzenianie się malware w przypadku przyszłego ataku.
Zarządzanie incydentami nie kończy się na technicznych aspektach — musi być zintegrowaniem organizacyjnym. Procedura musi być znana wszystkim pracownikom, zespół IRT musi być regularnie szkolony i testowany, a działania naprawcze z postmortem muszą być rzeczywiście wdrożone, nie tylko zalecane. Organizacje, które to robią, mogą znacznie zmniejszyć czas odzyskiwania i limit szkód w przypadku ataku, a tym samym chronić swoją reputację i finansową sytuację.